
搜索到
77
篇与
的结果
-
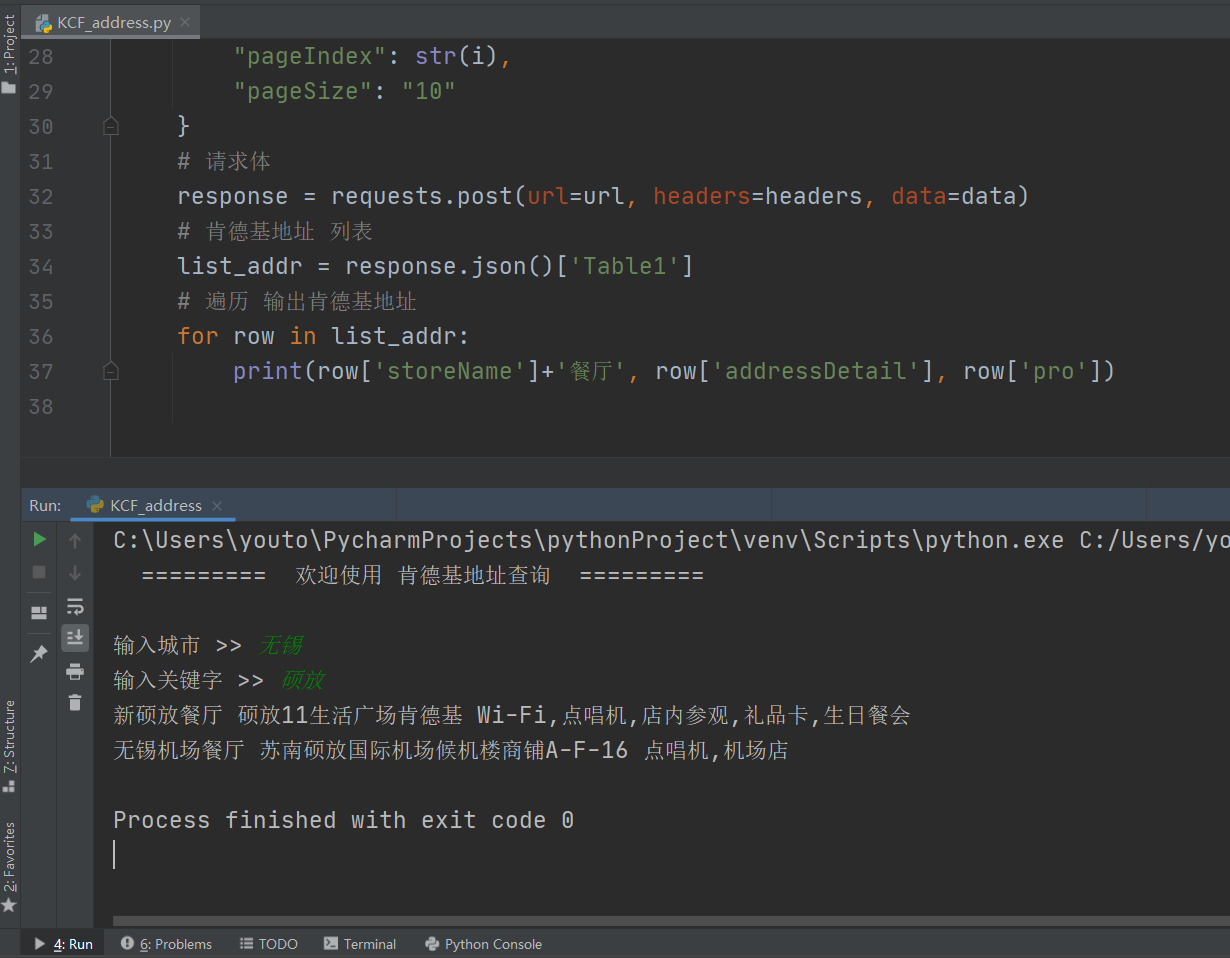
 爬取肯德基地址 简单获取肯德基地址 """ 作者:Acha 时间:2021-2-15 功能:查询肯德基地址信息 """ import requests # 肯德基URL url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' # 提示进入操作界面 print(" ========= 欢迎使用 肯德基地址查询 =========", '\n') # 请求头 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)" " AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/87.0.4280.141" " Safari/537.36"} # 城市,关键字 查询 city = str(input("输入城市 >> ")) keyword = str(input("输入关键字 >> ")) # 查询前 5 页地址 for i in range(5): # 动态参数 data = { "cname": city, "pid": '', "keyword": keyword, "pageIndex": str(i), "pageSize": "10" } # 请求体 response = requests.post(url=url, headers=headers, data=data) # 肯德基地址 列表 list_addr = response.json()['Table1'] # 遍历 输出肯德基地址 for row in list_addr: print(row['storeName']+'餐厅', row['addressDetail'], row['pro'])
爬取肯德基地址 简单获取肯德基地址 """ 作者:Acha 时间:2021-2-15 功能:查询肯德基地址信息 """ import requests # 肯德基URL url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' # 提示进入操作界面 print(" ========= 欢迎使用 肯德基地址查询 =========", '\n') # 请求头 headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)" " AppleWebKit/537.36 (KHTML, like Gecko)" " Chrome/87.0.4280.141" " Safari/537.36"} # 城市,关键字 查询 city = str(input("输入城市 >> ")) keyword = str(input("输入关键字 >> ")) # 查询前 5 页地址 for i in range(5): # 动态参数 data = { "cname": city, "pid": '', "keyword": keyword, "pageIndex": str(i), "pageSize": "10" } # 请求体 response = requests.post(url=url, headers=headers, data=data) # 肯德基地址 列表 list_addr = response.json()['Table1'] # 遍历 输出肯德基地址 for row in list_addr: print(row['storeName']+'餐厅', row['addressDetail'], row['pro']) -
MySQL 用户和权限管理 用户和权限管理 用户作用 登录mysql 管理mysql 用户定义 用户名@'白名单' 写法: wordpress@'%' wordpress@'localhost' wordpress@'127.0.0.1' wordpress@'10.0.0.%' wordpress@'10.0.0.5%' wordpress@'10.0.0.0/255.255.254.0' wordpress@'10.0.%' 用户管理 创建用户 mysql> create user ac@'10.0.0.%' identified by 'sa'; 说明:8.0以前,可以自动创建用户并授权 mysql> grant all on *.* to ac@'10.0.0.%' identified by 'sa'; 查询用户 mysql> select user,host from mysql.user; 修改用户密码 mysql> alter user ac@'10.0.0.%' identified by 'sa'; 删除用户 mysql> drop user ac@'10.0.0.%' ; 权限管理 权限列表 ALL SELECT,INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, SHUTDOWN, PROCESS, FILE, REFERENCES, INDEX, ALTER, SHOW DATABASES, SUPER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER, CREATE TABLESPACE 授权命令 例:grant all on *.* to ac@'10.0.0.%' identified by 'sa' with grant option; 说明:grant [权限] on [作用目标] to [用户] identified by [密码] with grant option 授权需求 创建一个管理员用户root,可以通过10网段,管理数据库. grant SELECT,INSERT, UPDATE, DELETE on wordpress.* to wordpress@'10.0.0.%' identified by '123'; 创建一个应用用户wordpress,可以通过10网段,wordpress库下的所有表进行SELECT,INSERT, UPDATE, DELETE. grant SELECT,INSERT, UPDATE, DELETE on wordpress.* to wordpress@'10.0.0.%' identified by '123'; 权限回收 show grants for wordpress@'10.0.0.%'; mysql> revoke delete on wordpress.* from 'wordpress'@'10.0.0.%'; mysql> show grants for wordpress@'10.0.0.%'; MySQL 的启动和关闭 正常启停 sys -v mysql.server start ---> mysqld_safe ---> mysqld system mysql.service ---> mysqld 需要依赖于 /etc/my.cnf 维护 mysqld_safe 例:修改密码mysqld_safe --skip-grant-tables --skip-networking & 将参数临时加到命令行,命令行的优先级高 初始化配置 初始化作用 影响数据库的启动 影响到客户端的功能 初始化方法 初始化配置文件(例如/etc/my.cnf) 启动命令行上进行设置(例如:mysqld_safe mysqld) 预编译时设置(仅限于编译安装时设置) 配置文件格式 [标签] xxx=xxx [标签] xxx=xxx 标签归类 服务器端: [mysqld] [mysqld_safe] [server] 客户端: [mysql] [mysqladmin] [mysqldump] [client] 模板文件 (5.7) # 服务器端配置 [mysqld] # 用户 user=mysql # 软件安装目录 basedir=/application/mysql # 数据路径 datadir=/data/mysql/data # socket文件位置 socket=/tmp/mysql.sock # 服务器id号 server_id=6 # 短口号 port=3306 # 客户端配置 [mysql] # socket文件位置 socket=/tmp/mysql.sock 配置文件读取顺序 查询: mysqld --help --verbose |grep my.cnf /etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf 强制使用自定义配置文件 --defautls-file [root@db01 tmp]# mysqld_safe --defaults-file=/tmp/aa.txt & MySQL的连接管理 mysql连接命令 注意:提前应该将用户授权做好 # 授权 mysql> grant all on *.* to root@'10.0.0.%' identified by '123'; # TCPIP mysql -uroot -p -h 10.0.0.51 -P3306 # Socket mysql -uroot -p -S /tmp/mysql.sock 客户端工具 dbforger sqlyog navicat
-
MySQL 体系结构 内容介绍: C/S 结构 实例构成 SQL语句分类 三层结构 逻辑存储结构 物理存储结构 innodb(段页区) C/S 结构 连接方式: TCP/IP mysql -u [用户名] -p [密码] -h [主机] -P [端口] Socket mysql -u [用户名]-p [密码] -S /tmp/mysql.sock 实例构成 mysqld + master thread + 干活的Thread + 预分配的内存 守护进程 主进程 进程 内存 SQL语句 结构化的查询语言 DQL 数据查询语言 DDL 数据定义语言 DML 数据操作语言 DCL 数据控制语言 例如:mysql> select user,host from mysql.user; 三层结构 连接层 连接协议 - Socket - TCP/IP 验证用户名(root@localhost)密码合法性,进行授权表匹配 派生一个专用连接线程(接收SQL,返回结果) SQL层 验证SQL语法和SQL_MODE 验证语义 验证权限 解析器进行语句解析,生成执行计划(解析树) 优化器(各种算法,基于执行代价),根据算法,找到代价最低的执行计划 CUP IO MEM 执行器按照优化器选择执行计划,执行SQL语句,得出获取数据的方法 提供query cache(默认关闭),一般不开,会用redis 记录操作日志(binlog),默认关闭 存储引擎层 与物理硬件交互 根据SQL层提供的取数据的方法;获取数据返回给SQL;结构化成表,连接层线程返回给用户 逻辑存储结构 库 表 列 数据行 表属性 物理存储结构 库:使用 FS 上的目录来表示 表: MyISAM(ext2) user.frm : 存储的表结构(列,列属性) user.MYD : 存储的数据记录 user.MYI : 存储索引 InnoDB(XFS) time_zone.frm : 存储的表结构(列,列属性) time_zone.ibd : 存储的数据记录和索引 ibdata1 : 数据字典信息 innodb(段页区) 区:16K 页:64个区组成,大小为1M 段:多个连续的页组成(分区表除外)
-
爬取51job岗位信息 提示:岗位链接的xpath表达式会经常变更 # coding=utf-8 """ 时间:2020/11/13 作者:wz 功能:使用python爬虫爬取51job岗位信息 """ import requests from lxml import etree from urllib import parse import time def get_html(url, encoding='utf-8'): """ 获取每一个 URL 的 html 源码 : param url:网址 : param encoding:网页源码编码方式 : return: html 源码 """ # 定义 headers headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Mobile Safari/537.36'} # 调用 requests 依赖包的get方法,请求该网址,返回 response response = requests.get(url, headers=headers) # 设置 response 字符编码 response.encoding = encoding # 返回 response 的文本 return response.text def crawl_each_job_page(job_url): # 定义一个 job dictionary job = {} # 调用 get_html 方法返回具体的html文本 sub_response = get_html(job_url) # 将 html 文本转换成 html sub_html = etree.HTML(sub_response) # 获取薪资和岗位名称 JOB_NAME = sub_html.xpath('//div[@class="j_info"]/div/p/text()') if len(JOB_NAME) > 1: job['SALARY'] = JOB_NAME[1] job['JOB_NAME'] = JOB_NAME[0] else: job['SALARY'] = '##' job['JOB_NAME'] = JOB_NAME[0] # 获取岗位详情 FUNC = sub_html.xpath('//div[@class="m_bre"]/span/text()') job['AMOUNT'] = FUNC[0] job['LOCATION'] = FUNC[1] job['EXPERIENCE'] = FUNC[2] job['EDUCATION'] = FUNC[3] # 获取公司信息 job['COMPANY_NAME'] = sub_html.xpath('//div[@class="info"]/h3/text()')[0].strip() COMPANY_X = sub_html.xpath('//div[@class="info"]/div/span/text()') if len(COMPANY_X) > 2: job['COMPANY_NATURE'] = COMPANY_X[0] job['COMPANY_SCALE'] = COMPANY_X[1] job['COMPANY_INDUSTRY'] = COMPANY_X[2] else: job['COMPANY_NATURE'] = COMPANY_X[0] job['COMPANY_SCALE'] = '##' job['COMPANY_INDUSTRY'] = COMPANY_X[1] # 设置来源 job['FROM'] = '51job' # 获取ID job_url = job_url.split('/')[-1] id = job_url.split('.')[0] job['ID'] = id # 获取岗位描述 DESCRIPTION = sub_html.xpath('//div[@class="c_aox"]/article/p/text()') job['DESCRIPTION'] = "".join(DESCRIPTION) # 打印 爬取内容 print(str(job)) # 将爬取的内容写入到文本中 # f = open('D:/51job.json', 'a+', encoding='utf-8') # f.write(str(job)) # f.write('\n') # f.close() # main 函数启动 if __name__ == '__main__': # 输入关键词 key = 'python' # 编码调整 key = parse.quote(parse.quote(key)) # 提示开始 print('start') # 默认访问前3页 for i in range(1, 4): # 初始网页第(i)页 page = 'https://search.51job.com/list/080200,000000,0000,00,9,99,' + str(key) + ',2,' + str(i) + '.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=' # 调用 get_html 方法返回第 i 页的html文本 response = get_html(page) # 使用 lxml 依赖包将文本转换成 html html = etree.HTML(response) # 获取每个岗位的连接列表 sub_urls = html.xpath('//div[@class="list"]/a/@href') # 判断 sub_urls 的长度 if len(sub_urls) == 0: continue # for 循环 sub_urls 每个岗位地址连接 for sub_url in sub_urls: # 调用 crawl_each_job_page 方法,解析每个岗位 crawl_each_job_page(sub_url) # 睡 3 秒 time.sleep(3) # 提示结束 print('end.')
-