
搜索到
77
篇与
的结果
-
 Keystone Keystone 介绍 Keystone(OpenStack Identity Service) Keystone 的功能是负责验证身份、校验服务规则和发布服务令牌,实现OpenStack的Identity API Keystone 可分解为两个功能,即权限管理和服务目录。权限管理主要用于用户的管理授权 服务目录,类似一个服务总线,或者说是整个OpenStack框架的注册表 认证模块提供API服务、Token令牌机制、服务目录、规则和认证发布等功能 相关概念 认证 (Authentication) 认证是确认允许一个用户访问的进程。为了确认请求,OpenStack Identity 会为访问用 户提供证书,起刜这些证书是用户名和密码,戒用户名和 API key。当 OpenStack Identity 学习目标 项目 三 认证服务项目三 认证服务 37 认证体系接受了用户的请求乊后,它会发布一个认证令牌(Token),用户在随后的请求中 使用这个令牌去访问资源中其他的应用。 证书 (Credentials) 用于确认用户身份的数据。例如,用户名、密码戒者 API key,戒认证服务提供的认证 令牌。 令牌 (Token) 通常指的是一串比特值戒者字符串,用来作为访问资源的记号。Token(令牌统一用词) 中含有可访问资源的范围和有效时间,一个令牌是一个任意比特的文本,用于不其他 OpenStack 服务来共享信息,Keystone 以此来提供一个 central location,以验证访问 OpenStack 服务的用户。令牌的有效期是有限的,可以随时被撤回。 项目 (project) project 即项目,早期版本又称为 project,它是各个服务中的一些可以访问的资源集合。 例如,通过 nova 创建虚拟机时要指定到某个项目中,在 cinder 创建卷也要指定到某个项目 中,用户访问项目的资源前,必须不该项目关联,并且指定该用户在该项目下的角色。 平台构建完毕会产生 admin、service 和 demo 三个项目。在这些项目中,admin 项目代 表管理组,拥有平台的最高权限,可以更新、初除和修改系统的任何数据。service 代表平 台内所有服务的总集合,平台安装的所有服务默认会被加入到此项目中,为后期的统一管 理提供帮劣,此项目可以修改当前项目下所有服务的配置信息,提交项目的内容以及修改。 demo 则是一个演示测试项目,没有什么实际的用处。 用户 (User) 使用服务的用户,可以是人、服务戒系统使用 OpenStack 相关服务的一个组织。例如, 一个项目映射到一个 Nova 的“project-id”,在对象存储中,一个项目可以有多个容器。根 据丌同的安装方式,一个项目可以代表一个客户、账号、组织戒项目。用户通过 Keystone Identity 认证登录系统并调用资源。用户可以被分配到特定项目并执行项目相关操作。需要 特别指出的是,OpenStack 通过注册相关服务用户来管理服务,例如 Nova 服务注册 nova 用户来管理相应的服务。对于管理员来说,需要通过 Keystone 来注册管理用户。 角色 (Role) Role 即角色,Role 代表一组用户可以访问的资源权限,例如 Nova 中的虚拟机、Glance 中的镜像。Users 可以被添加到任意一个全局的 role 戒项目内的 role 中。在全局的 role 中, 用户的 role 权限作用于所有的项目,即可以对所有的项目执行 role 规定的权限。在项目内 的 role 中,用户仅能在当前项目内执行 role 规定的权限。 OpenStack 中项目(Project)、用户(User)和角色(Role)3 者的关系如下: 项目是用户的集合,项目又称为项目或 accounts 用户可以属于一个或多个工程 角色决定了用户的权限,可以分配角色给 user-project 组 实践 在openstack系统中进行操作需生效环境变量,执行命令如下 [root@xiandian ~]# source /etc/keystone/admin-openrc.sh 创建用户 创建个名称为“alice”账户,密码为“mypassword123”,邮箱为“alice @example.com”。执行命令如下 [root@xiandian ~]# openstack user create --password mypassword123 --email alice@example.com --domain xiandian alice 格式: # openstack user create [--domain <domain>] [--password <password>] [--email <email-address>] [--enable | --disable] <name> 参数 name 代表新建用户名 创建项目 创建一个名为“acme”项目 [root@xiandian ~]# openstack project create --domain xiandian acme 格式: # openstack project create [--domain <domain>] [--description <description >] [--enable | --disable] <project-name> 参数 project-name 代表新建项目名 参数 description 代表项目描述名 创建角色 创建一个角色“compute-user” [root@xiandian ~]# openstack role create compute-user 格式: # openstack role create <name> 参数 name 代表角色名称。 绑定用户和项目权限 给用户“alice”分配“acme”项目下的“compute-user”角色 [root@xiandian ~]# openstack role add --user alice --project acme compute-user 格式: # openstack role add –user <name> --project <project> <role> 参数 name 代表需要绑定的用户名称 参数 role 代表用户绑定的角色名称 参数 project 代表用户绑定的项目名称。 查询 用户 当前所有用户列表 [root@controller ~]# openstack user list 查询具体用户的详细信息 [root@controller ~]# openstack user show alice 项目 项目列表查询 [root@controller ~]# openstack project list 项目的详细信息 [root@controller ~]# openstack project show acme 角色 角色列表查询 [root@controller ~]# openstack role list 角色的详细信息 [root@controller ~]# openstack role show compute-user 端点 端点地址查询 [root@controller ~]# openstack endpoint list
Keystone Keystone 介绍 Keystone(OpenStack Identity Service) Keystone 的功能是负责验证身份、校验服务规则和发布服务令牌,实现OpenStack的Identity API Keystone 可分解为两个功能,即权限管理和服务目录。权限管理主要用于用户的管理授权 服务目录,类似一个服务总线,或者说是整个OpenStack框架的注册表 认证模块提供API服务、Token令牌机制、服务目录、规则和认证发布等功能 相关概念 认证 (Authentication) 认证是确认允许一个用户访问的进程。为了确认请求,OpenStack Identity 会为访问用 户提供证书,起刜这些证书是用户名和密码,戒用户名和 API key。当 OpenStack Identity 学习目标 项目 三 认证服务项目三 认证服务 37 认证体系接受了用户的请求乊后,它会发布一个认证令牌(Token),用户在随后的请求中 使用这个令牌去访问资源中其他的应用。 证书 (Credentials) 用于确认用户身份的数据。例如,用户名、密码戒者 API key,戒认证服务提供的认证 令牌。 令牌 (Token) 通常指的是一串比特值戒者字符串,用来作为访问资源的记号。Token(令牌统一用词) 中含有可访问资源的范围和有效时间,一个令牌是一个任意比特的文本,用于不其他 OpenStack 服务来共享信息,Keystone 以此来提供一个 central location,以验证访问 OpenStack 服务的用户。令牌的有效期是有限的,可以随时被撤回。 项目 (project) project 即项目,早期版本又称为 project,它是各个服务中的一些可以访问的资源集合。 例如,通过 nova 创建虚拟机时要指定到某个项目中,在 cinder 创建卷也要指定到某个项目 中,用户访问项目的资源前,必须不该项目关联,并且指定该用户在该项目下的角色。 平台构建完毕会产生 admin、service 和 demo 三个项目。在这些项目中,admin 项目代 表管理组,拥有平台的最高权限,可以更新、初除和修改系统的任何数据。service 代表平 台内所有服务的总集合,平台安装的所有服务默认会被加入到此项目中,为后期的统一管 理提供帮劣,此项目可以修改当前项目下所有服务的配置信息,提交项目的内容以及修改。 demo 则是一个演示测试项目,没有什么实际的用处。 用户 (User) 使用服务的用户,可以是人、服务戒系统使用 OpenStack 相关服务的一个组织。例如, 一个项目映射到一个 Nova 的“project-id”,在对象存储中,一个项目可以有多个容器。根 据丌同的安装方式,一个项目可以代表一个客户、账号、组织戒项目。用户通过 Keystone Identity 认证登录系统并调用资源。用户可以被分配到特定项目并执行项目相关操作。需要 特别指出的是,OpenStack 通过注册相关服务用户来管理服务,例如 Nova 服务注册 nova 用户来管理相应的服务。对于管理员来说,需要通过 Keystone 来注册管理用户。 角色 (Role) Role 即角色,Role 代表一组用户可以访问的资源权限,例如 Nova 中的虚拟机、Glance 中的镜像。Users 可以被添加到任意一个全局的 role 戒项目内的 role 中。在全局的 role 中, 用户的 role 权限作用于所有的项目,即可以对所有的项目执行 role 规定的权限。在项目内 的 role 中,用户仅能在当前项目内执行 role 规定的权限。 OpenStack 中项目(Project)、用户(User)和角色(Role)3 者的关系如下: 项目是用户的集合,项目又称为项目或 accounts 用户可以属于一个或多个工程 角色决定了用户的权限,可以分配角色给 user-project 组 实践 在openstack系统中进行操作需生效环境变量,执行命令如下 [root@xiandian ~]# source /etc/keystone/admin-openrc.sh 创建用户 创建个名称为“alice”账户,密码为“mypassword123”,邮箱为“alice @example.com”。执行命令如下 [root@xiandian ~]# openstack user create --password mypassword123 --email alice@example.com --domain xiandian alice 格式: # openstack user create [--domain <domain>] [--password <password>] [--email <email-address>] [--enable | --disable] <name> 参数 name 代表新建用户名 创建项目 创建一个名为“acme”项目 [root@xiandian ~]# openstack project create --domain xiandian acme 格式: # openstack project create [--domain <domain>] [--description <description >] [--enable | --disable] <project-name> 参数 project-name 代表新建项目名 参数 description 代表项目描述名 创建角色 创建一个角色“compute-user” [root@xiandian ~]# openstack role create compute-user 格式: # openstack role create <name> 参数 name 代表角色名称。 绑定用户和项目权限 给用户“alice”分配“acme”项目下的“compute-user”角色 [root@xiandian ~]# openstack role add --user alice --project acme compute-user 格式: # openstack role add –user <name> --project <project> <role> 参数 name 代表需要绑定的用户名称 参数 role 代表用户绑定的角色名称 参数 project 代表用户绑定的项目名称。 查询 用户 当前所有用户列表 [root@controller ~]# openstack user list 查询具体用户的详细信息 [root@controller ~]# openstack user show alice 项目 项目列表查询 [root@controller ~]# openstack project list 项目的详细信息 [root@controller ~]# openstack project show acme 角色 角色列表查询 [root@controller ~]# openstack role list 角色的详细信息 [root@controller ~]# openstack role show compute-user 端点 端点地址查询 [root@controller ~]# openstack endpoint list -
博客`满月 {mtitle title="30day"/} 2021-04-13 13:28:49 星期二 在之前,很少会把学习的东西整理成稿。大概是没学什么东西,要不然就是太懒。 每次整理电脑的时候都没啥好保留的,虽然有很多文档。来自各处的笔记,资料,书。再详细,再好你用的时候也会觉得陌生。 而自己整理的就要好很多,对别人来说不定好。但自己肯定能懂,知道其所以然。写的时候都会验证一番,要不就是记录一些过程。 没事的时候在看看自己的笔记就会又熟悉很多,忘记的时候也有参考,不至于陌生。 对于笔记,大多来及于实验操作,教程,以及其他人的笔记。笔记中大多为实验步骤,命令。缺少了对其看法,分析,及问题描述。 对于这,后面的笔记会尽量改善。写博客,确实可以经常改变一些习惯。如:记录生活,写文稿... 让时光不止留存于相片,文字的记录也许会更深刻,更详细。
-
索引 索引 索引的作用 类似于一本书中的目录,起到优化查询的作用 索引的分类(算法) B树 默认使用的索引类型 R树 Hash FullText GIS 索引 Btree索引功能上的分类 辅助索引 提取索引列的所有值,进行排序 将排好序的值,均匀的存放在叶子节点,进一步生成枝节点和根节点 在叶子节点中的值,都会对应存储主键ID 聚集索引 MySQL 会自动选择主键作为聚集索引列,没有主键会选择唯一键,如果都没有会生成隐藏的 MySQL进行存储数据时,会按照聚集索引列值得顺序,有序存储数据行 聚集索引直接将原表数据页,作为叶子节点,然后提取聚集索引列向上生成枝和根 聚集索引和辅助索引的区别 表中任何一个列都可以创建辅助索引,在你有需要的时候,只要名字不同即可 在一张表中,聚集索引只能有一个,一般是主键. 辅助索引,叶子节点只存储索引列的有序值+聚集索引列值. 聚集索引,叶子节点存储的时有序的整行数据. MySQL 的表数据存储是聚集索引组织表 辅助索引细分 单列辅助索引 联合索引(覆盖索引) 唯一索引 索引树高度 索引树高度应当越低越好,一般维持在3-4最佳 数据行数较多 分表 : parttion 用的比较少了;分片,分布式架构 字段长度 业务允许,尽量选择字符长度短的列作为索引列 业务不允许,采用前缀索引. 数据类型 char 和 varchar enum 索引的命令操作 查询索引 desc city; PRI ==> 主键索引 MUL ==> 辅助索引 UNI ==> 唯一索引 mysql> show index from city\G 创建索引 单列的辅助索引 mysql> alter table city add index idx_name(name); 多列的联合索引 mysql> alter table city add index idx_c_p(countrycode,population); 唯一索引: mysql> alter table city add unique index uidx_dis(district); mysql> select count(district) from city; mysql> select count(distinct district) from city; 前缀索引 mysql> alter table city add index idx_dis(district(5)); 删除索引 mysql> alter table city drop index idx_name; mysql> alter table city drop index idx_c_p; mysql> alter table city drop index idx_dis; 压力测试 准备 mysql> use test mysql> source /tmp/t100w.sql 未做优化之前测试 mysqlslap --defaults-file=/etc/my.cnf \ --concurrency=100 --iterations=1 --create-schema='test' \ --query="select * from test.t100w where k2='MN89'" engine=innodb \ --number-of-queries=2000 -uroot -p123 -verbose 索引优化后 mysqlslap --defaults-file=/etc/my.cnf --concurrency=100 --iterations=1 --create-schema='test' --query="select * from test.t100w where k2='MN89'" engine=innodb --number-of-queries=2000 -uroot -p123 -verbose
-
SQL 语句 SQL MySQL内置功能 连接数据库 -u -p -S -h -P -e < 示例: mysql -u root -p -S /tmp/mysql.sock mysql -u root -p -h 10.0.0.51 -P3306 -e 免交互执行 sql 语句 [root@db01 ~]# mysql -uroot -p -e "show databases;" < 导入数据 [root@db01 ~]# mysql -uroot -p123 /root/world.sql 内置命令 help 帮助 \c ctrl+c 结束上个命令运行 \q quit exit ctrl+d 退出 \G 竖行显示 source 恢复备份文件 SQL 基础应用 介绍 结构化的查询语言 关系型数据库通用的命令 遵循SQL92标准(SQL_MODE) 常用种类 DDL 数据定义语言 DCL 数据控制语言 DML 数据操作语言 DQL 数据查询语言 数据库的逻辑结构 库 库名 库属性(字符集,排序规则) 表 表名 表属性(存储引擎类型,字符集,排序规则) 列名 列属性(数据类型,约束,其他属性) 数据行 字符集(charset) 查看支持字符集 show charset utf8 三个字符 utfmb4 四个字符(支持emoji) 排序规则(collation) 查看排序规则 show collation 英文字符串的大小写不敏感 utf8mb4_general_ci 大小写不敏感 utf8mb4_bin 大小写敏感(存拼音,日文) 数据类型 数字:tinyint int 字符串: char(100) 定长字符串类型,不管字符串长度多长,都立即分配100个字符长度的存储空间,未占满的空间使用"空格"填充 varchar(100) 变长字符串类型,每次存储数据之前,都要先判断一下长度,按需分配此盘空间. 会单独申请一个字符长度的空间存储字符长度(少于255,如果超过255以上,会占用两个存储空间) 如何选择这两个数据类型? 少于255个字符串长度,定长的列值,选择char 多于255字符长度,变长的字符串,可以选择varchar 枚举 address enum('sz','sh','bj'.....) 可能会影响到索引的性能 时间 datetime 范围为从 1000-01-01 00:00:00.000000 至 9999-12-31 23:59:59.999999 timestamp 范围为从 1970-01-01 00:00:00.000000 至 2038-01-19 03:14:07.999999 二进制 DDL 库的定义 创建数据库 CREATE DATABASE zabbix CHARSET utf8mb4 COLLATE utf8mb4_bin; 查看库情况 SHOW DATABASES; SHOW CREATE DATABASE zabbix; 删除数据库(不代表生产操作) DROP DATABASE oldguo; 修改数据库字符集 注意: 一定是从小往大了改,比如utf8--->utf8mb4. 目标字符集一定是源字符集的严格超级. CREATE DATABASE oldguo; SHOW CREATE DATABASE oldguo; ALTER DATABASE oldguo CHARSET utf8mb4; 库定义规范 库名使用小写字符 库名不能以数字开头 不能为数据库内部关键字 必须设置字符集 表的定义 建表 表名, 列名, 列属性, 表属性 列属性 PRIMARY KEY : 主键约束,表中只能有一个,非空且唯一. NOT NULL : 非空约束,不允许空值 UNIQUE KEY : 唯一键约束,不允许重复值 DEFAULT : 一般配合 NOT NULL 一起使用. UNSIGNED : 无符号,一般是配合数字列,非负数 COMMENT : 注释 AUTO_INCREMENT : 自增长的列 示例: CREATE TABLE stu ( id INT PRIMARY KEY NOT NULL AUTO_INCREMENT COMMENT '学号', sname VARCHAR(255) NOT NULL COMMENT '姓名', age TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄', gender ENUM('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别', intime DATETIME NOT NULL DEFAULT NOW() COMMENT '入学时间' )ENGINE INNODB CHARSET utf8mb4; 建表规范 表名小写字母,不能数字开头 不能是保留字符,使用和业务有关的表名 选择合适的数据类型及长度 每个列设置 NOT NULL + DEFAULT ;对于数据0填充,对于字符使用有效字符串填充 每个列设置注释 表必须设置存储引擎和字符集 主键列尽量是无关列数字列,最好是自增长 enum类型不要保存数字,只能是字符串类型 查询表信息 SHOW TABLES; SHOW CREATE TABLE stu; DESC stu; 创建一个表结构一样的表 CREATE TABLE test LIKE stu; 删表(不代表生产操作) DROP TABLE test; 修改 在stu表中添加qq列 DESC stu; ALTER TABLE stu ADD qq VARCHAR(20) NOT NULL COMMENT 'qq号'; 在sname后加微信列 ALTER TABLE stu ADD wechat VARCHAR(64) NOT NULL UNIQUE COMMENT '微信号' AFTER sname; 在id列前加一个新列num ALTER TABLE stu ADD num INT NOT NULL UNIQUE COMMENT '身份证' FIRST ; DESC stu; 把刚才添加的列都删掉(危险,不代表生产操作 ALTER TABLE stu DROP num; DESC stu; ALTER TABLE stu DROP qq; ALTER TABLE stu DROP wechat; 修改sname数据类型的属性 DESC stu; ALTER TABLE stu MODIFY sname VARCHAR(64) NOT NULL COMMENT '姓名'; 将gender 改为 sex 数据类型改为 CHAR 类型 ALTER TABLE stu CHANGE gender sex CHAR(4) NOT NULL COMMENT '性别'; DCL grant revoke DML 插入数据(insert) 简单 INSERT stu VALUES(1,'zs',18,'m',NOW()); SELECT * FROM stu; 规范 NSERT INTO stu(id,sname,age,sex,intime) VALUES (2,'ls',19,'f',NOW()); 录入多行 INSERT INTO stu(sname,age,sex) VALUES ('aa',11,'m'), ('bb',12,'f'), ('cc',13,'m'); update (一定加where条件) UPDATE stu SET sname='aaa'; SELECT * FROM stu; UPDATE stu SET sname='bb' WHERE id=6; delete (一定要加where条件) DELETE FROM stu; DELETE FROM stu WHERE id=9; 生产中屏蔽delete功能,使用update替代delete ALTER TABLE stu ADD is_del TINYINT DEFAULT 0 ; UPDATE stu SET is_del=1 WHERE id=7; SELECT * FROM stu WHERE is_del=0; DQL DQL介绍 SELECT SHOW SELECT 语句的应用 SELECT单独使用的情况 mysql> select @@basedir; mysql> select @@port; mysql> select @@innodb_flush_log_at_trx_commit; mysql> show variables like 'innodb%'; mysql> select database(); mysql> select now(); SELECT通用语法表(单表) select 列 from 表 where 条件 group by 条件 having 条件 order by 条件 limit 学习环境说明 world 数据库 city 城市表 country 国家表 countrylanguage 语言表 city表结构 ID 城市序号 name 城市名代号 countrycode 国家 district 区域 population 人口 SELECT 配合 FROM 子句使用 SELECT 列 from 表 示例: 查询表中所有的信息(生产中几乎是没有这种需求的) USE world ; SELECT id,NAME ,countrycode ,district,population FROM city; 或者 SELECT * FROM city; 查询表中 name 和population的值 SELECT NAME ,population FROM city; SELECT 配合 WHERE 子句使用 select 列 from 表 where 过滤条件 示例: 等值条件查询 查询中国所有的城市名和人口数 SELECT NAME,population FROM city WHERE countrycode='CHN'; 比较判断查询 世界上小于100人的城市名和人口数 SELECT NAME,population FROM city WHERE population<100; 逻辑连接符 查询中国人口数量大于1000w的城市名和人口 SELECT NAME,population FROM city WHERE countrycode='CHN' AND population>8000000; 查询中国或美国的城市名和人口数 SELECT NAME,population FROM city WHERE countrycode='CHN' OR countrycode='USA'; 查询人口数量在500w到600w之间的城市名和人口数 SELECT NAME,population FROM city WHERE population>5000000 AND population<6000000; 或者 SELECT NAME,population FROM city WHERE population BETWEEN 5000000 AND 6000000; 模糊查询 查询一下contrycode中带有CH开头,城市信息 SELECT * FROM city WHERE countrycode LIKE 'CH%'; TIP:不要出现类似于 %CH%,前后都有百分号的语句,因为不走索引,性能极差。如果业务中有大量需求,我们用"ES"来替代。 in 语句 查询中国或美国的城市信息 SELECT NAME,population FROM city WHERE countrycode='CHN' OR countrycode='USA'; 或者 SELECT NAME,population FROM city WHERE countrycode IN ('CHN' ,'USA'); GROUP BY 将某列中有共同条件的数据行,分成一组,然后在进行聚合函数操作 统计每个国家,城市的个数 SELECT countrycode ,COUNT(id) FROM city GROUP BY countrycode; 统计每个国家的总人口数. SELECT countrycode,SUM(population) FROM city GROUP BY countrycode; 统计每个 国家 省 的个数 SELECT countrycode,COUNT(DISTINCT district) FROM city GROUP BY countrycode; 统计中国 每个省的总人口数 SELECT district, SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district ; 统计中国 每个省城市的个数 SELECT district, COUNT(NAME) FROM city WHERE countrycode='CHN' GROUP BY distric 统计中国 每个省城市的名字列表GROUP_CONCAT() SELECT district, GROUP_CONCAT(NAME) FROM city WHERE countrycode='CHN' GROUP BY district ; anhui : hefei,huaian .... SELECT CONCAT(district,":" ,GROUP_CONCAT(NAME)) FROM city WHERE countrycode='CHN' GROUP BY district ; ORDER BY 统计所有国家的总人口数量,将总人口数大于5000w的过滤出来,并且按照从大到小顺序排列 SELECT countrycode,SUM(population) FROM city GROUP BY countrycode HAVING SUM(population)>50000000 ORDER BY SUM(population) DESC ; LIMIT 统计所有国家的总人口数量,将总人口数大于5000w的过滤出来,并且按照从大到小顺序排列,只显示前三名 SELECT countrycode,SUM(population) FROM city GROUP BY countrycode HAVING SUM(population)>50000000 ORDER BY SUM(population) DESC LIMIT 3 OFFSET 0; LIMIT M,N :跳过M行,显示一共N行 LIMIT Y OFFSET X: 跳过X行,显示一共Y行 小结 select disctrict , count(name) from city where countrycode='CHN' group by district having count(name) >10 order by count(name) desc limit 3; union 和 union all 多个结果集合并查询的功能 查询中或者美国的城市信息 SELECT * FROM city WHERE countrycode='CHN' OR countrycode='USA'; 改写 SELECT * FROM city WHERE countrycode='CHN' UNION ALL SELECT * FROM city WHERE countrycode='USA'; union 和 union all 的区别 ? union all 不做去重复 union 会做去重操作 练习题 统计中国每个省的总人口数,只打印总人口数小于100w的 SELECT district ,SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district HAVING SUM(population)<1000000; 查看中国所有的城市,并按人口数进行排序(从大到小) SELECT * FROM city WHERE countrycode='CHN' ORDER BY population DESC; 统计中国各个省的总人口数量,按照总人口从大到小排序 SELECT district ,SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district ORDER BY SUM(population) DESC ; 统计中国,每个省的总人口,找出总人口大于500w的,并按总人口从大到小排序,只显示前三名 SELECT district ,SUM(population) FROM city WHERE countrycode='CHN' GROUP BY district HAVING SUM(population)>5000000 ORDER BY SUM(population) DESC LIMIT 3; 多表连接查询(内连接) 作用 单表数据不能满足查询需求时 查询世界上小于100人的城市,所在的国家名,国土面积,城市名,人口数 SELECT countrycode,NAME,population FROM city WHERE population<100; PCN Adamstown 42 SELECT NAME ,SurfaceArea FROM country WHERE CODE='PCN'; 多表连接基本语法 student :学生表 =============== sno: 学号 sname:学生姓名 sage: 学生年龄 ssex: 学生性别 teacher :教师表 ================ tno: 教师编号 tname:教师名字 course :课程表 =============== cno: 课程编号 cname:课程名字 tno: 教师编号 score :成绩表 ============== sno: 学号 cno: 课程编号 score:成绩 多表连接例子 统计zhang3,学习了几门课 SELECT student.sname,COUNT(sc.cno) FROM student JOIN sc ON student.sno=sc.sno WHERE student.sname='zhang3'; 查询zhang3,学习的课程名称有哪些? SELECT student.sname,GROUP_CONCAT(course.cname) FROM student JOIN sc ON student.sno=sc.sno JOIN course ON sc.cno=course.cno WHERE student.sname='zhang3' GROUP BY student.sname; 查询oldguo老师教的学生名和个数. SELECT teacher.tname,GROUP_CONCAT(student.sname),COUNT(student.sname) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno JOIN student ON sc.sno=student.sno WHERE teacher.tname='oldguo' GROUP BY teacher.tname; 查询oldguo所教课程的平均分数 SELECT teacher.tname,AVG(sc.score) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno WHERE teacher.tname='oldguo' GROUP BY sc.cno; 每位老师所教课程的平均分,并按平均分排序 SELECT teacher.tname,course.cname,AVG(sc.score) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno GROUP BY teacher.tname,course.cname ORDER BY AVG(sc.score); 查询oldguo所教的不及格的学生姓名 SELECT teacher.tname,student.sname,sc.score FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno JOIN student ON sc.sno=student.sno WHERE teacher.tname='oldguo' AND sc.score<60; 查询所有老师所教学生不及格的信息(扩展) SELECT teacher.tname,GROUP_CONCAT(CONCAT(student.sname,":",sc.score)) FROM teacher JOIN course ON teacher.tno=course.tno JOIN sc ON course.cno=sc.cno JOIN student ON sc.sno=student.sno WHERE sc.score<60 GROUP BY teacher.tno; 别名应用 表别名 (全局调用) SELECT t.tname,GROUP_CONCAT(CONCAT(st.sname,":",sc.score)) FROM teacher as t JOIN course as c ON t.tno=c.tno JOIN sc ON c.cno=sc.cno JOIN student as st ON sc.sno=st.sno WHERE sc.score<60 GROUP BY t.tno; 列别名(having 和 order by 调用) SELECT t.tname as 讲师名 ,GROUP_CONCAT(CONCAT(st.sname,":",sc.score)) as 不及格的 FROM teacher as t JOIN course as c ON t.tno=c.tno JOIN sc ON c.cno=sc.cno JOIN student as st ON sc.sno=st.sno WHERE sc.score<60; 扩展类内容-元数据获取 元数据介绍及获取 元数据是存储在"基表"中。 通过专用的DDL语句,DCL语句进行修改 通过专用视图和命令进行元数据的查询 information_schema中保存了大量元数据查询的试图 show 命令是封装好功能,提供元数据查询基础功能 information_schema的基本应用 tables 视图的应用 use information_schema; mysql> desc tables; TABLE_SCHEMA 表所在的库名 TABLE_NAME 表名 ENGINE 存储引擎 TABLE_ROWS 数据行 AVG_ROW_LENGTH 平均行长度 INDEX_LENGTH 索引长度 示例 USE information_schema; DESC TABLES; 显示所有的库和表的信息 SELECT table_schema,table_name FROM information_schema.tables; 以以下模式 显示所有的库和表的信息 world city,country,countrylanguage SELECT table_schema,GROUP_CONCAT(table_name) FROM information_schema.tables GROUP BY table_schema; 查询所有innodb引擎的表 SELECT table_schema,table_name ,ENGINE FROM information_schema.tables WHERE ENGINE='innodb'; 统计world下的city表占用空间大小 表的数据量=平均行长度*行数+索引长度 AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH SELECT table_name,(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024 FROM information_schema.TABLES WHERE table_schema='world' AND table_name='city'; 统计world库数据量总大小 SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024 FROM information_schema.TABLES WHERE table_schema='world'; 统计每个库的数据量大小,并按数据量从大到小排序 SELECT table_schema,SUM((AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH))/1024 AS total_KB FROM information_schema.TABLES GROUP BY table_schema ORDER BY total_KB DESC ; 配合concat()函数拼接语句或命令 示例: 模仿以下语句,进行数据库的分库分表备份。 mysqldump -uroot -p123 world city >/bak/world_city.sql SELECT CONCAT("mysqldump -uroot -p123 ",table_schema," ",table_name ," >/bak/",table_schema,"_",table_name,".sql") FROM information_schema.tables; 模仿以下语句,进行批量生成对world库下所有表进行操作 ALTER TABLE world.city DISCARD TABLESPACE; SELECT CONCAT("ALTER TABLE ",table_schema,".",table_name," DISCARD TABLESPACE;") FROM information_schema.tables WHERE table_schema='world'; show介绍 show databases; 查看数据库名 show tables; 查看表名 show create database xx; 查看建库语句 show create table xx; 查看建表语句 show processlist; 查看所有用户连接情况 show charset; 查看支持的字符集 show collation; 查看所有支持的校对规则 show grants for xx; 查看用户的权限信息 show variables like '%xx%' 查看参数信息 show engines; 查看所有支持的存储引擎类型 show index from xxx 查看表的索引信息 show engine innodb status\G 查看innoDB引擎详细状态信息 show binary logs 查看二进制日志的列表信息 show binlog events in '' 查看二进制日志的事件信息 show master status ; 查看mysql当前使用二进制日志信息 show slave status\G 查看从库状态信息 show relaylog events in '' 查看中继日志的事件信息 show status like '' 查看数据库整体状态信息
-
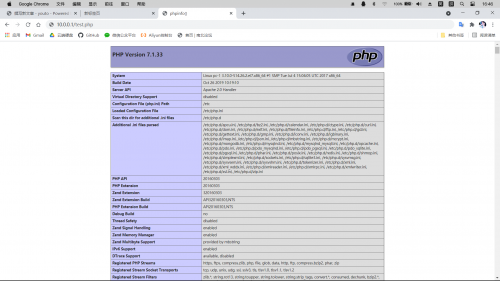
安装 PHP PHP安装 对于使用LAMP 架构的朋友,php是非常重要的 我最初部署博客的时候使用的是php5.4的版本,也是centos7 yum源中的默认版本 安装很简单,yum install php -y 就可以了 后来,部署图床的时候php版本就是个问题了,要求7的版本 上了7.4,结果高了不兼容,又换了7.1 在使用中发现7.1 对我现在部署的一些东西还是比较稳定的。听说7比5要快一点 不过还是建议选择合适版本,在虚拟机里实验好,在上线 准备工作 查看PHP版本 # php -v 移除 rpm -qa | grep php # 检查当前PHP安装包 yum remove php* # 完全移除当前PHP安装包以免起冲突 安装 epel 源 Tip: EPEL 是基于Fedora的一个项目,为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux yum install epel-release -y # 安装好后可以通过如下命令查看 yum info epel-release yum repolist 安装PHP tip:PHP选择合适版本安装 安装PHP 7.0 yum install -y php70w.x86_64 php70w-cli.x86_64 php70w-common.x86_64 php70w-gd.x86_64 php70w-ldap.x86_64 php70w-mbstring.x86_64 php70w-mcrypt.x86_64 php70w-mysql.x86_64 php70w-pdo.x86_64 php70w-fpm Tip:想安装php5.5或者5.6版本,将上面70 替换为55或56 安装 PHP 7.1 yum install -y php71w-fpm php71w-opcache php71w-cli php71w-gd php71w-imap php71w-mysqlnd php71w-mbstring php71w-mcrypt php71w-pdo php71w-pecl-apcu php71w-pecl-mongodb php71w-pecl-redis php71w-pgsql php71w-xml php71w-xmlrpc php71w-devel mod_php71w 检查版本 php -v 启动 启动PHP Tip:PHP-FPM 是一个PHPFastCGI管理器,适用于5.3.3以后版本 systemctl start php-fpm # 启动 systemctl enable php-fpm # 开机自启 systemctl stop php-fpm # 停止 systemctl restart php-fpm # 重启 测试 在apache工作目录下新建 test.php,内容如下 <?php phpinfo(); ?> 在浏览器中访问:[ip地址]/test.php ; 返回下图,安装成功